
MS Teams : l’angle mort de votre stratégie d’observabilité ?
Les équipes IT le constatent quotidiennement : Microsoft Teams s’est imposé comme l’épine dorsale de la collaboration en entreprise. En 2024, la plateforme compte désormais 320 millions d’utilisateurs actifs mensuels, soit une croissance constante depuis la pandémie.
Cette adoption massive s’accompagne d’un revers inattendu : l’explosion des tickets de support. Audio haché, vidéo figée, partage d’écran défaillant etc. Et pourtant, dans l’Admin Center Microsoft, tous les indicateurs restent au vert.
Résultat :
- des utilisateurs mécontents,
- des helpdesks débordés,
- des managers qui doutent de la fiabilité de leurs outils,
- des équipes réseau qui peinent à agir faute de données précises,
- et, bien souvent, des politiques de renouvellement d’équipements (casques, PC, routeurs) mises en place sans avoir identifié la root cause réelle.
Ce paradoxe révèle un problème plus profond : les outils de monitoring actuels ne couvrent pas les spécificités de Teams, laissant les équipes IT dans l’incapacité de diagnostiquer efficacement les problèmes d’appels et de réunions.
Pourquoi vos utilisateurs se plaignent (même quand tout est “vert”)
Des tickets IT en hausse constante pour des incidents Teams
Selon les retours terrain des équipes IT, les incidents liés à Teams représentent aujourd’hui une part croissante des tickets de niveau 1 :
- « Impossible d’entendre mon interlocuteur en réunion »
- « Le partage d’écran rame, est-ce lié au VPN ? »
- « Teams déconnecte en pleine présentation client »
- “Par où est passé ma communication Teams ?”
Ces tickets partagent un point commun : ils sont difficiles à résoudre rapidement et chronophage à traiter. Selon un rapport Gartner, le temps moyen de résolution d’un incident collaboratif peut dépasser 2 heures. L’absence de visibilité technique précise oblige les équipes support à procéder par élimination, allongeant les temps de résolution et frustrant les utilisateurs.
Quand les outils standards montrent leurs limites
Le Call Quality Dashboard (CQD) de Microsoft constitue la référence officielle pour monitorer Teams. Cet outil fournit des métriques agrégées utiles sur la qualité des appels, mais présente plusieurs limitations dans un contexte entreprise :
Forces du CQD :
- Vue d’ensemble des tendances qualité
- Métriques standardisées
- Intégration native à l’écosystème Microsoft
Le CQD de Microsoft est censé aider, mais en pratique :
- Il ne permet pas un diagnostic en temps réel : données disponibles seulement 30 minutes après l’appel, excluant le diagnostic en temps réel
- Il ignore la dimension réseau/site : pas de corrélation avec l’infrastructure réseau par site
- La télémétrie est incomplète en cas de coupure réseau
👉 Concrètement, si une filiale à Madrid souffre de latence réseau qui dégrade les appels, CQD ne vous le montrera pas clairement.
Le problème réseau : 60% des incidents Teams ont une origine locale
La dimension site, grande oubliée du monitoring
Une étude menée par Zscaler révèle que plus de 60% des dégradations Teams proviennent de problèmes réseau locaux : WiFi surchargé, routeurs défaillants, bande passante insuffisante ou VPN congestionné.
Cette réalité terrain contraste avec l’approche centralisée des outils de monitoring traditionnels, qui agrègent les données sans distinction géographique.

Cas d’usage typique : le diagnostic impossible
Scénario : Un commercial en déplacement à Lyon signale des appels inaudibles lors d’une présentation client importante.
Processus de résolution traditionnel :
- Vérification du CQD → Pas d’anomalie globale détectée
- Test de la connexion utilisateur → Bande passante correcte
- Vérification du matériel → Casque et microphone fonctionnels
- Escalade vers le niveau 2 → Investigation réseau approfondie
- Découverte après 2h : Le routeur WiFi du bureau de Lyon était défaillant
Temps de résolution : 2h15 pour un problème matériel basique, faute de visibilité réseau granulaire.
Solutions DEX : utiles mais pas suffisantes pour Teams
L’approche Digital Employee Experience
Les outils DEX comme Nexthink ou Aternity apportent une vision précieuse de l’expérience utilisateur globale. Ils excellent dans le monitoring des performances générales (temps de démarrage, utilisation CPU, santé des applications).
Atouts des solutions DEX :
- Vision holistique de l’expérience utilisateur
- Corrélation entre performances matérielles et ressenti
- Tableau de bord unifié pour toutes les applications
Limites pour Teams spécifiquement :
- Pas d’analyse des codecs audio/vidéo utilisés
- Métriques réseau génériques (non adaptées à la VoIP)
- Absence de corrélation entre qualité perçue et métriques techniques Teams
Le besoin d’une approche hybride
Plutôt que de remplacer les outils existants, l’approche la plus pragmatique consiste à compléter le stack de monitoring avec des solutions spécialisées d’observabilité sur Teams.
Cette stratégie permet de :
- Conserver les investissements DEX existants
- Combler l’angle mort spécifique aux communications unifiées
- Fournir aux équipes réseau des données actionnables
ℹ️ Le saviez-vous ?
L’observabilité est la capacité à comprendre le comportement d’un système complexe en analysant ses signaux internes (logs, métriques, traces).
- Le monitoring dit “ça marche / ça ne marche pas”.
- L’observabilité explique “pourquoi ça ne marche pas et où agir”.
👉 Dans le cas de Microsoft Teams, c’est la différence entre constater qu’un appel a échoué et savoir en 3 minutes si c’est dû au WiFi, au VPN, au réseau du site ou à un service Microsoft.
Comment combler cet angle mort ?
L’adoption massive de Teams transforme les exigences de monitoring IT. Les outils traditionnels, bien qu’utiles, ne suffisent plus à garantir une expérience utilisateur optimale.
Les organisations les plus matures adoptent une approche en trois niveaux :
- Monitoring global : CQD Microsoft + solutions DEX existantes
- Observabilité spécialisée : Outils dédiés Teams avec corrélation réseau
- Automation : Diagnostic automatisé et résolution proactive
Cette stratégie permet de réduire les temps de résolution de 70% en moyenne, tout en améliorant significativement la satisfaction utilisateur.
L’apport de l’observabilité
Avec MS Teams Observability :
- Une cartographie interactive des sites affichant la conformité NPA (Network Performance Assessment).
- Une vue réseau dédiée (distribution de conformité, qualité des appels, causes racines, volume d’appels).
- Une analyse détaillée par call, avec la cartographie des flux, les utilisateurs impactés ou impactants, toutes les métrique des calls.

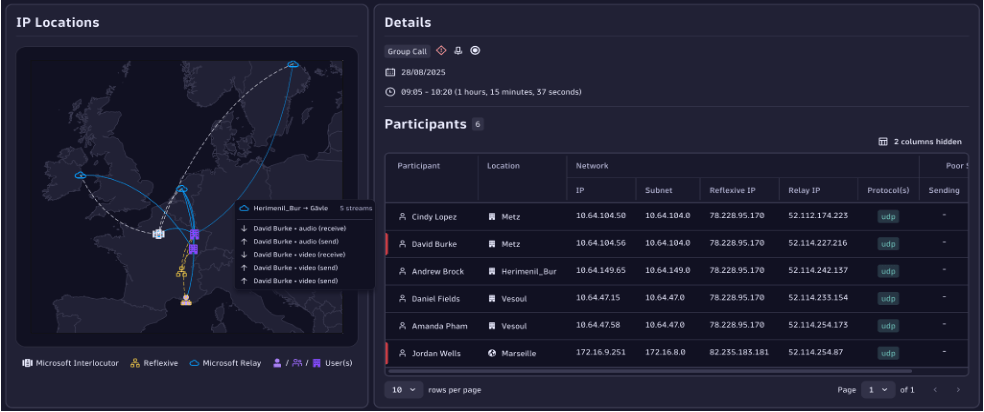

Visualiser, diagnostiquer, agir en 3 minutes
Grâce à la méthode waterfall, enrichie par l’IA Copilot, chaque appel peut être rejoué comme une timeline :
- qui était connecté,
- depuis quel réseau,
- avec quelle qualité de flux audio/vidéo.
Résultat : une root cause analysis en moins de 3 minutes.

Cas d’usage
- Helpdesk : moins d’escalades, plus de tickets résolus dès le premier niveau.
- Managers : amélioration de l’expérience collaborateur, moins de réunions gâchées.
- NOC/Network teams : KPI et compliance réseau clairs pour prioriser les actions correctives.
- Direction IT : meilleure maîtrise de l’adoption Teams et optimisation des licences.
Conseils pratiques pour vos équipes IT
- Équipe Helpdesk: Formez-les à lire la timeline waterfall pour diagnostiquer un appel sans escalader.
- Équipe Réseau/NOC: Mettez en place des alertes site-level (latence, perte de paquets) pour intervenir avant que les utilisateurs ne se plaignent et auditez proactivement l’ensemble de vos sites en 1 clic !
- Managers: Suivez les KPI d’adoption Teams (usage par département, qualité perçue) pour mesurer l’impact sur la productivité.
- CIO/DSI : Intégrez Teams Observability dans votre stack (Dynatrace, Splunk) pour unifier la visibilité et réduire les coûts liés aux outils DEX monolithiques.

Conclusion : l’observabilité Teams, la pièce manquante de votre monitoring collaboratif
Les outils existants (CQD, Nexthink, Aternity) apportent une partie des réponses mais laissent un angle mort critique : la visibilité réseau et site-level.
Avec MS Teams Observability, vous comblez ce manque et gagnez en rapidité de diagnostic, en efficacité opérationnelle et en expérience collaborateur.
Dans un monde où Teams est devenu aussi vital que la messagerie ou la téléphonie, ne pas observer Teams, c’est prendre un risque majeur.
Réduisez vos temps de résolution et améliorez l’expérience Teams de vos collaborateurs. Découvrez MS Teams Observability par Phenisys.
FAQ – Observabilité Microsoft Teams
1. Comment diagnostiquer un problème d’appel Microsoft Teams ?
La méthode la plus efficace consiste à utiliser une solution d’observabilité dédiée. Contrairement au simple monitoring, elle permet d’observer l’appel sous forme de timeline waterfall, d’analyser chaque flux (audio, vidéo, partage d’écran) et d’identifier en quelques minutes la cause racine : réseau local, VPN, WiFi, latence ou service Microsoft en panne.
2. Pourquoi le Call Quality Dashboard (CQD) de Microsoft n’est-il pas suffisant ?
Le CQD fournit des statistiques agrégées utiles, mais il a plusieurs limites :
- Pas de visibilité fine site par site
- Pas de diagnostic en temps réel
- Pas de lien clair entre métriques et expérience utilisateur
Pour les équipes IT, cela signifie beaucoup de tickets ouverts sans réponse rapide.