Pourquoi ça rame ?
C’est LA question !
Mais si ça « rame », c’est tout de même que ça « marchotte »…
Et si ça marche mais que l’utilisateur se plaint (toujours à raison évidemment ! A moins d’avoir à faire à un PEBCAK…), alors la réponse va être un peu plus compliqué que si ça ne marchait pas du tout ! Forcément.
On va tout de même essayer d’apporter une réponse générale à la question « Pourquoi ? ».
Et juste avant de dire pourquoi, il convient de dire tout de même Quoi ? et Combien ? « ça rame ».
Ca rame combien ?
Dire que « ça rame », ça veut dire que l’application est lente. Plus précisément, certaines ou toutes les opérations unitaires d’une application (on appelle ça une transaction applicative) sont plus lentes que la normale. Ah ! Il peut donc y avoir une norme ! Intéressant.
Et on parle donc d’une métrique liée à un temps… On a donc une unité de mesure, la seconde, et la métrique qui la porte a un nom, c’est le Temps de Réponse applicatif vu de l’utilisateur. Et on peut même considérer qu’il y a plusieurs type de Temps de Réponse :
- un Temps de réponse global de l’application, bien que ça n’ait pas forcément de sens tant les transactions peuvent varier de forme et de contenu,
- un Temps de Réponse d’une transaction applicative particulière, c’est déjà plus précis, mais il peut y en avoir une grande diversité,
- enfin, un Temps de Réponse d’un scénario applicatif, c’est à dire un enchainement type et représentatif de transactions applicatiives choisies. On s’approche ici du véritable vécu et donc ressenti de l’utilisateur.
Malheureusement, il est rare que les organisations informatiques définissent un scénario type de transactions applicatives et qu’elle disposent d’une « baseline », c’est à dire de cette fameuse norme de ce que devrait être le temps de réponse applicatif vu de l’utilisateur pour ce scénario de transactions.
Et pourtant, un utilisateur le sait lui quand « ça rame » ! En définitive, cette baseline existe « dans sa tête » et est fonction de son expérience moyenne. Il faut donc croire l’utilisateur ! Même si c’est un retour parfois subjectif, il est valable.
Et biensûr, il existe des outils pour avoir une visibilité technique et donc objective sur ce Temps de Réponse applicatif vu de l’utilisateur. Il y a même des moyens de mesurer manuellement ou automatiquement des baselines, pour comparaison ultérieure. Mais cela méritera un article dédié au Temps de Réponse Applicatif et sa mesure.
Intéressons-nous donc pour l’instant au pourquoi.
CNS breakdown : ventilation Client-Network-Server
Pour commencer, il convient de distinguer plusieurs origines « horizontalement ». Il y a en effet un cheminement dans l’utilisation de l’application, dont chaque partie peut introduire des retards et donc augmenter le fameux Temps de Réponse Applicatif vu de l’utilisateur.

- le poste du client (C), l’utilisateur en dépend, son ressenti aussi. Qui n’a jamais expérimenté que, rien que pour faire une opération toute local à sa machine, déjà, « ça rame » ! Donc le poste client peut être une cause, pas toujours la plus simple, d’un problème de Temps de Réponse applicatif.
- l’ensemble du réseau (N), du LAN du site, en passant par des routeurs, un réseau étendu, dit WAN avec ses boucles locales, son backbone et ses opérateurs, puis l’infrastructure de sécurité autorisant ou non les trafics vers les serveurs, et enfin le LAN avec ses VLAN et tout le tintouin du Datacenter où sont hébergé les serveurs d’application. Ca en fait des causes possibles de ralentissements !
- « le » serveur (S), qui bien souvent et de plus en plus n’est pas 1 seul serveur mais plusieurs, les uns derrières les autres (application multi-tiers) et/ou les uns à coté des autres (grappe ou cluster pour partager la charge et couvrir les risques de panne), et qui plus est, il est aussi désormais souvent « virtuel », c’est à dire purement logiciel à coté d’autres serveurs virtuels partageant les ressources d’une grosse machine physique qui ne fait que ça de donner ses ressources. Bref, une belle complexité de causes en perspective aussi.
On comprend bien que cette ventilation « CNS » du temps de réponse applicatif est une base importante pour dichotomiser la cause du problème de performance. Et il y a encore matière à distinguer à l’intérieur de chacune de ces 3 compostantes différentes sous parties impliquées.
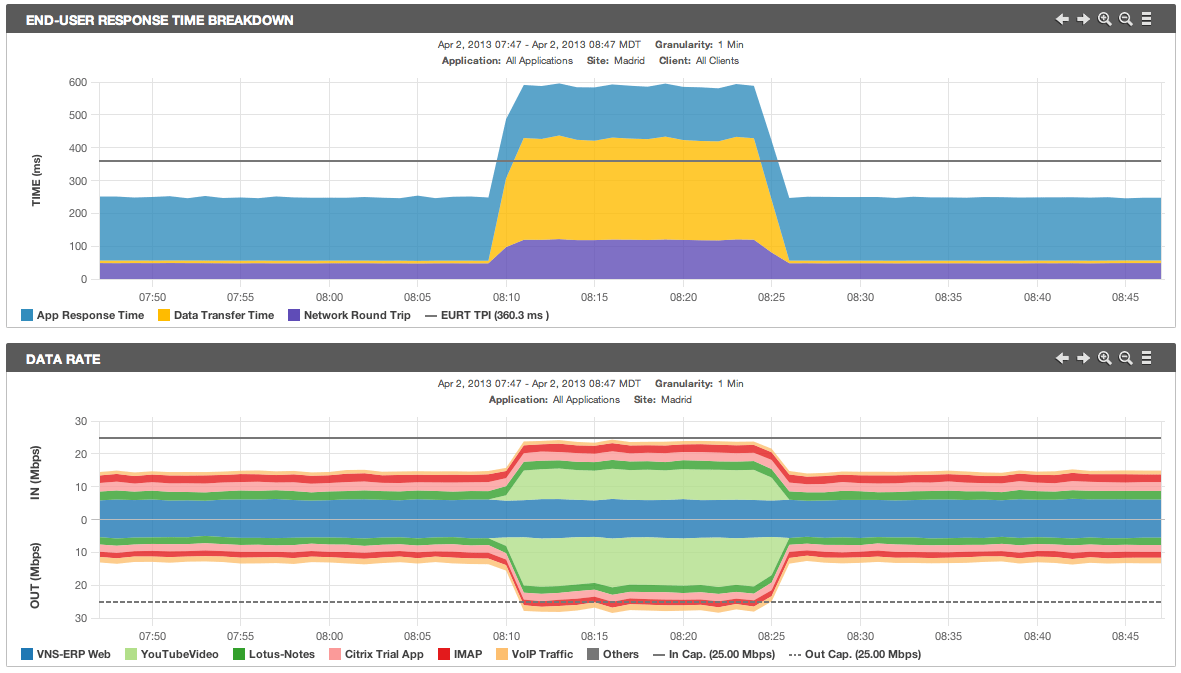
C’est « le débit » biensûr !
Aaaah le débit ! La bande passante ! Ca au moins, tout le monde connait : si c’est lent, c’est que le réseau n’est pas assez rapide, pas assez de débit. Il suffit d’augmenter la bande passante et puis voilà !
Oui, mais non.
D’abord, le réseau a plus de caractéristiques que seulement son débit : sa latence, son taux de perte de paquets, sa gigue, etc.
Bien, mais concentrons-nous malgré tout sur la seule bande passante. L’application peut être gourmande ou non en bande passante (transferts de fichiers par exemple), elle peut utiliser des petits (Citrix) ou des gros paquets (HTTP, FTP), peut être fragile face à la concurrence (temps réel, transactionnel , voix sur IP) ou robuste. Et l’utilisateur peut voir l’effet du manque de bande passante (sur la voix, c’est audible ! sur Citrix, ça bloque) ou pas du tout (un mail peut bien arriver 30 secondes plus tard, quelle différence !).
Et la bande passante peut manquer avec différentes subtilités et différents effets :
- La saturation : la bande passante manque complètement et en continu, potentiellement sous l’effet d’une seule application vorace ! Et classiquement, on ne peut plus travailler, tout est lent. Ce cas est souvent le plus facile à diagnostiquer et corriger une fois la source identifiée.
- La congestion : la nuance du terme est plus du niveau de la convention, mais le cas est concrètement différent. Le manque de ressource est épisodique, il apparait sous l’effet de compétitions entre applications aux protocoles et comportements différents. L’effet est également variable suivant l’application : la congestion est fatale pour la voix sur IP rendue inutilisable, pénible sous Citrix, mais potentiellement peu perceptible sur du web basique et totalement, invisible sur le mail.La congestion peut-être difficile à détecter car elle peut disparaitre sous l’effet des moyennes dans les graphes ! Elle peut être aussi délicate à corriger car elle est le résultat de plusieurs sources consommatrices de débit, il faut donc contrôler subtilement les applications en priorisant les flux par exemple, ce qui demande une analyse et des moyens spéciaux.
- L’inflation : la bande passante peut aussi manquer « quoi qu’il arrive », même si on l’augmente, la soif des applications (certaines disons) n’est pas étanchées ! C’est un effet très pervers de TCP qui est ici à l’oeuvre dans les applications transférant de gros volumes. Naturellement, TCP cherche à occuper toute la place disponible tant qu’il n’y a pas congestion, et donc… il est juste normal d’atteindre tout le temps des niveaux de congestion quand on transfert beaucoup de données ! L’autre effet inflationniste n’est pas technique mais psychologique et vient des utilisateurs : donnez leur plus de ressources, un meilleur confort et hop, l’usage augmente ! Bref, il peut presque ne jamais y avoir assez de bande passante. Que faire ? Analyser et contrôler, encore.
Ainsi donc, la seule question de la bande passante, celle qui parait la plus évidente, peut encore se révéler subtile. Et personne ne veut payer un réseau plus gros avec un engagement à l’année ou plus pour se rendre compte que ça n’améliore pas la situation… Alors même qu’une analyse et un bon conseil aurait permis d’éviter avec une solution de priorisation ou une simple politique d’usage sur un firewall !
Visibilité et Contrôle, encore une fois, pour cette « simple » question de la bande passante sont des nécessités.
Et les protocoles, ils sont partout les protocoles !
Et oui, les protocoles sont partout ! A tous les étages… des couches OSI biensûr.
Et là le débat atteint des niveaux de complexité. Le réseau c’est généralement les couches jusqu’à IP, c’est à dire OSI 1, 2 et 3, soient Physique, Liaison de donnée et Réseau. L’application, elle, avec ses API fait des Sessions, de la Présentation et finalement des Application, soit OSI 5, 6 et 7. Et ça fait déjà pas mal de protocoles pour chacun lorsqu’il faut analyser un problème coté réseau et coté application.
Mais… et le niveau 4 ? Le Transport… TCP !
TCP, c’est cet inconnu de tous ! De l’application qui ne le voit pas, puisqu’elle s’adresse à des API ou au mieux ouvre des Sockets, point barre. Le transport et bien l’OS se débrouille. Et du Réseau qui est transparent pour tout IP, c’est promis ! Alors TCP et bien il se débrouille, non ?
Et bien justement ! TCP il se débrouille avec une bardée de mécanismes internes et d’algorythmes : Three Way Handshake, Slow Start, Congestion Avoidance, Selective ACK, Triple Duplicate ACK, Delayed ACK, Nagle’s Algorythm, Maximum Transmit and Receive Window, Frozen Window…
 Alors des effets de protocoles qui peuvent nuire aux performances, je ne vous fais pas plus le dessin… il peut y en avoir un certain nombre ! Il y a ceux du réseau, il y a ceux des applications et le pire, c’est qu’il y a aussi ceux qui ne sont ni l’un, ni l’autre !
Alors des effets de protocoles qui peuvent nuire aux performances, je ne vous fais pas plus le dessin… il peut y en avoir un certain nombre ! Il y a ceux du réseau, il y a ceux des applications et le pire, c’est qu’il y a aussi ceux qui ne sont ni l’un, ni l’autre !
L’enfer ces protocoles, l’enfer !
Que faire ? Les connaitre, c’est tout. Pour diagnostiquer, c’est mieux. Demandez a votre médecin comment il fait pour vous soigner ! Il a appris tous les mécanismes du corps, et leurs maladies…
Bavardages applicatifs et latence réseau, qui blâmer ?
Si enfin vous avez pu identifier que l’application, à travers ses couches protocolaires infernales, réalisait des bavardages in-tem-pes-tifs à travers le réseau (qui a dit CIFS ?), et que le-dit réseau avait une latence in-sup-por-table (qui a dit 3G ?), et que c’est pour cela que « Ca rame ! », alors bravo, vous avez un beau diagnostic !
Exemple, tout à fait pris au hasard… Vous browsez un répertoire du disque Z: en réseau à travers votre clé 3G : 200 allers-retours de transactions applicative x 200 millisecondes = 40 secondes… ça peut être long à attendre juste pour voir la liste des dossiers. Non ?
Mais voilà, vous avez aussi un responsable Système ou Application qui vous dit « C’est pas mon appli, c’est le réseau qui a une latence pourri, j’y peux rien ! » ; vous avez aussi un responsable Réseau qui vous dit « L’application doit fonctionner en réseau ? Et bien elle n’a qu’à pas être si bavarde, elle est mal écrite, c’est tout ! Je ne vais pas rapprocher la France de l’Asie, ni changer la vitesse de la lumière ! »
Alors, même quand on sait pourquoi ça rame… qui a raison ? Comment fait-on ?
Evidemment, je suis tenté de prendre position en faveur de la géographie du monde et de la vitesse de la lumière qui donne quelques bases solides au fonctionnement normal d’un réseau… et de l’application qui doit tourner dessus. Mais quand l’application utilise des protocoles ou API qu’il n’est pas facile de remettre à plat… il faut être un peu plus fin.
Les solutions existent, a peu près dans tous les cas. La plupart du temps, j’arrive même à proposer le choix à mes clients ! Mais une chose est sure il faut analyser très très précisément Qui, Quoi, Où et Pourquoi ça rame !
Alors, Pourquoi ça rame ? Application ou Réseau ?
Au final, la véritable cause, la réponse au « Pourquoi ? », c’est rarement juste « le réseau » !
Les techniciens et ingénieurs réseau, les responsables de département « Télécom et Reseaux » me comprendront : ça fait du bien d’en parler. Et pour en parler un peu plus, c’est tout l’objet de ce Blog d’aborder ces aspects de performance mal maitrisés ou méconnus qui ne sont pas juste causés par « le réseau ».
C’est aussi un sujet clé pour les DSI, qui bien souvent, se retrouvent face aux utilisateurs (par la voie hiérarchique d’un responsable de site ou de département métier !), avec leurs propres départements Réseau, Systèmes ou Applications qui se renvoient la balle et le ticket d’incident. Pour les plus organisés, en mode ITIL évidement, c’est le Problem Manager et ses comités d’experts qui patinent dans la choucroute, bien souvent pour un simple problème de méthodologie et d’expertise transverse dans l’Analyse de la Performance Applicative (APA).
Et enfin, il faut garder à l’esprit que, loi de Murphy oblige, si un problème vous remonte, il y a des chances non négligeables qu’il soit le cumul de plusieurs sources, pour un « emmerdement maximum »…
Alors, Pourquoi ça rame ? Pas si évident à dire.
Mais sinon, ça ne serait pas drôle. Et je ne serais pas là…